AI GGUF - LLM Model File Parser in C#
This GGUF file parser was written by Gyula Rábai for parsing and inspecting GGUF (GPT-Generated Unified Format) files commonly used for storing large language models. The parser can properly understand different data formats including qunatizatoin used in local AI model execution.
This GGUF file parser is used by Gyula Rabai's C# AI Inference Engine.
Download
Download (Exe): GGUFParser.zip
Download (Source): GGUFParser.zip
Github respository
https://github.com/mrgyularabai/GGUF-parserScreenshots
Overview
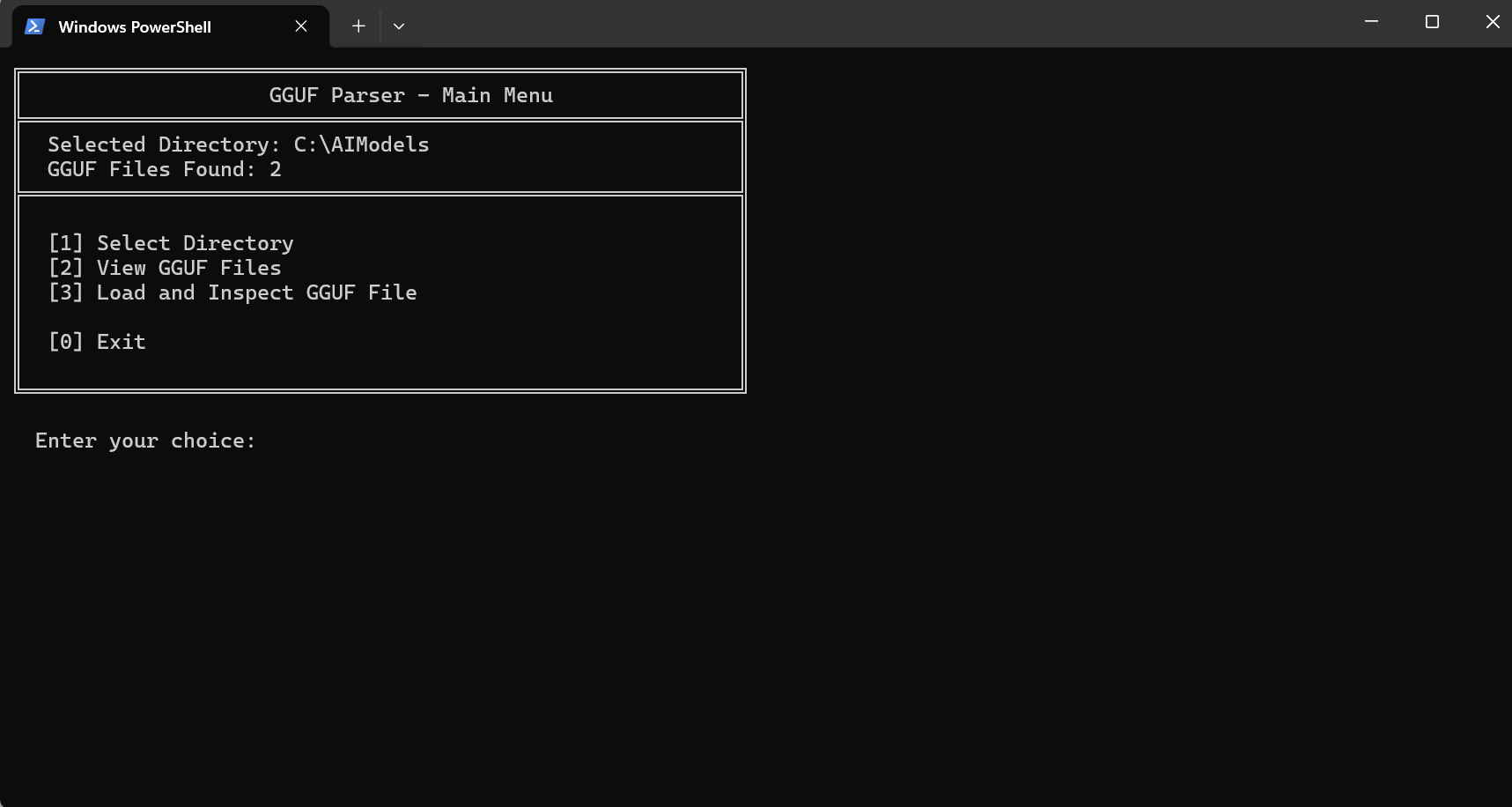
This project provides a comprehensive GGUF file parser with a user-friendly console interface. It allows you to:
- Scan directories for GGUF files
- Load and inspect GGUF model files
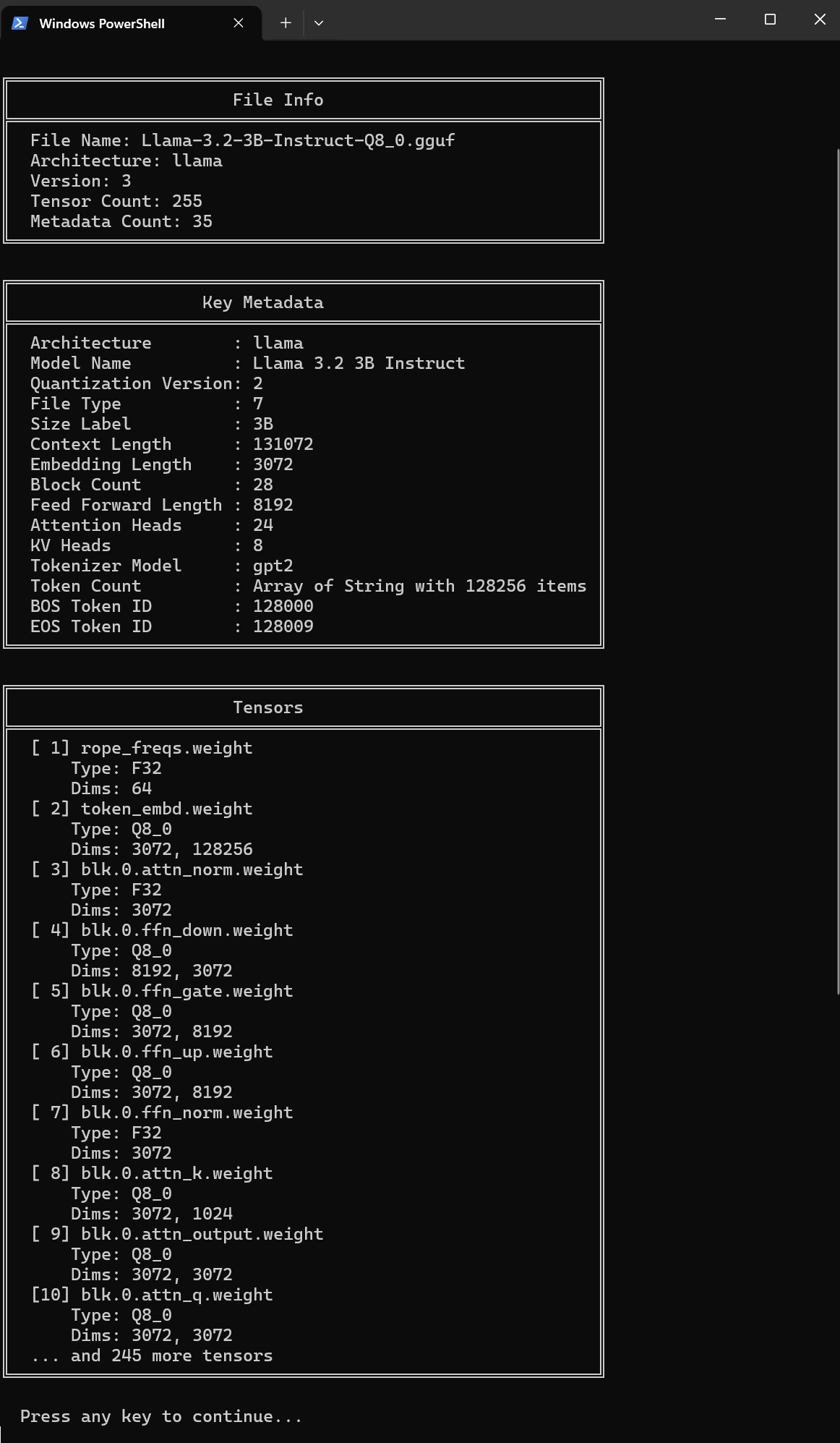
- View file metadata and tensor information
- Support for various quantization formats
Features
- Directory Scanning: Recursively search for
.gguffiles in any directory - File Inspection: Load and display detailed information about GGUF files
- Metadata Display: View key model metadata including:
- Architecture (e.g., llama, mistral, etc.)
- Model name
- Context length
- Embedding length
- Attention heads
- Tokenizer information
- Tensor Information: View tensor names, types, and dimensions
- Multi-format Support: Handles various GGUF file versions and quantization formats
Requirements
- .NET 8.0 SDK or later
- Windows, Linux, or macOS
Building
cd GGUFParser/GGUFParser
dotnet build
Running
dotnet runThe default directory for scanning is C:\AIModels. You can change this through the menu.
Usage
The application provides an interactive console menu:
- Select Directory - Choose a directory to scan for GGUF files
- View GGUF Files - List all found GGUF files in the selected directory
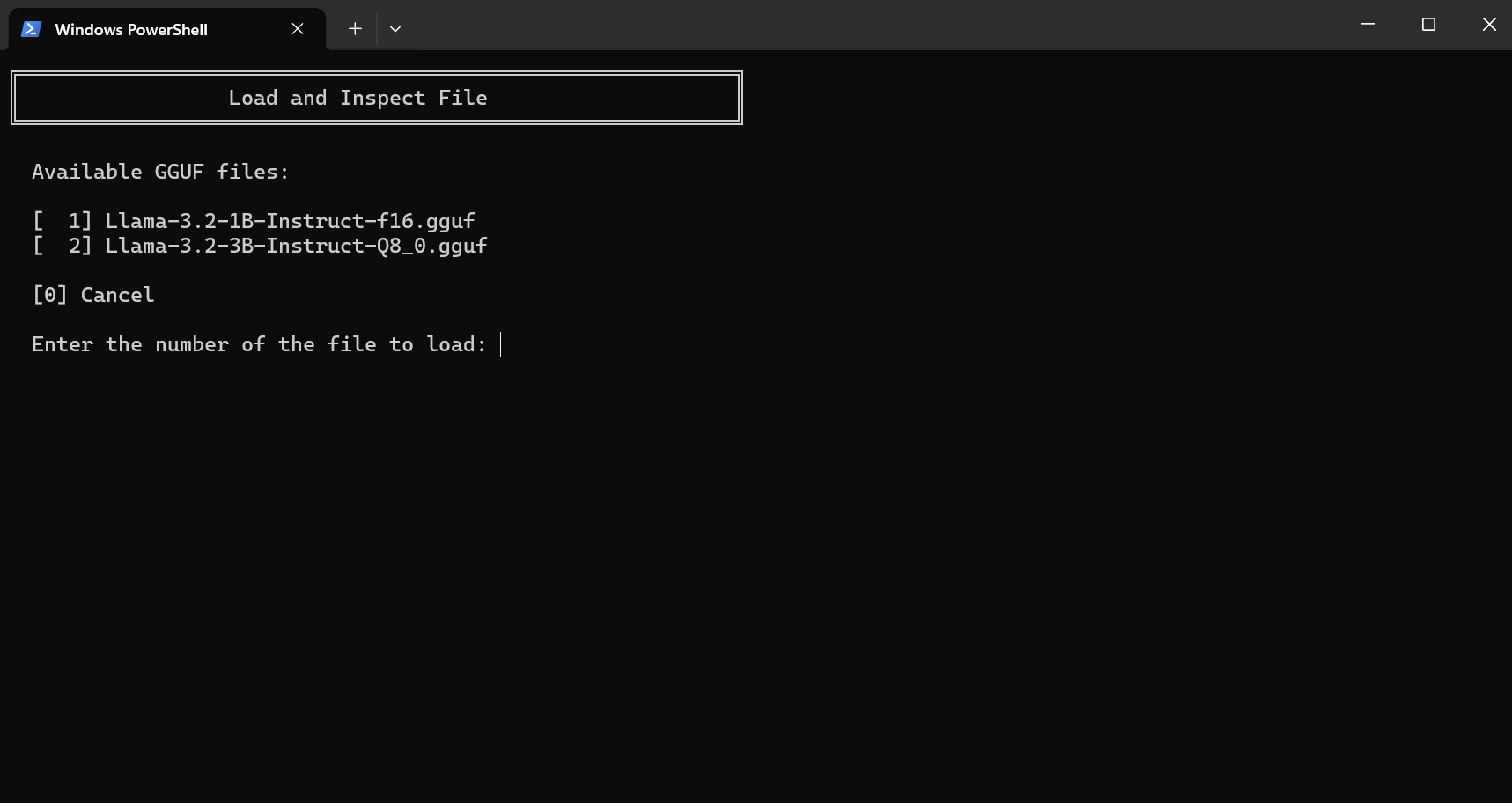
- Load and Inspect GGUF File - Load a specific GGUF file and view its details
- Exit - Close the application
Project Structure
GGUFParser/ ├── GGUFParser.sln ├── GGUFParser/ │ ├── Program.cs # Main application entry point │ ├── GGUFParser.csproj # Project file │ ├── AIMath/ # AI math operations and types │ ├── AINum/ # Numeric type implementations │ ├── GGUFFile/ # GGUF file parsing │ └── Matrix/ # Matrix operations
Key Components
GGUFFile
The core module for parsing GGUF files:
- OzGGUFFile - Main file handler
- OzGGUF_Tensor - Tensor representation
- OzGGUF_MD - Metadata handling
Numeric Types
Comprehensive support for different numeric formats:
- Floating point: Float16, Float32, Float64, BFloat16
- Integer: Int8, Int16, Int32, Int64
- Unsigned: UInt8, UInt16, UInt32, UInt64
- Quantized: Various IQ, KQ, RQ formats
Understanding the source code
To parse a GGUF file, the first step is to identify the metadata and load the model into RAM.
The GGUF file represents meta-data through first containing a magic number (uint32, ASCII equivalent of ’G’, ’G’, ’U’, ’F’ unsuprisingly). Then a file-format version number is provided as well as with the count of how many tensors are stored. Finally, the number of metadata entries is given. Each metadata entry then follows suit.
The metadata entries all have a name (GGUF String), a type (enum of uint32), and a value. All strings start with a uint64 giving the string’s length and then a UTF-8 sequence. Other metadata types are relatively self-explanatory with a uint64 representing an unsigned 64-bit integer. An array of other metadata-entries is also possible (used for storing the token vocabulary). Perhaps the most notable metadata entry is the architecture which can be used to identify what other entries to expect.
This is then followed by headers for each tensor in the file. A header consists of a name (gguf string), an uint32 representing the dimension count, a series of uint64 s representing the dimensions of each tensors, finally a datatype for the tensor (enum) and a file offset is given.
The code is as follows for reading the meta data stage:
The main function that is called for parsing the MDs (each function returns a bool indicating success):
public bool LoadHeadersFromStream(FileStream s, out string error)
{
//Parse Header
if (!ReadTo(s, out MagicNumber, out error)) return false;
if (!ReadTo(s, out VersionNumber, out error)) return false;
if (!ReadTo(s, out TensorCount, out error)) return false;
if (!ReadTo(s, out MDCount, out error)) return false;
//Parse Metadata
if (!parseMDs(s, out error)) return false;
//Parse Tensors
if (!parseTensors(s, out error)) return false;
_headerEnd = s.Position;
//Optional
parseArch(s, out error);
return true;
}
To read each type of meta data I use the following function:
bool ReadTo<T>(Stream s, out T i, out string error) where T : OzGGUF_Item
{
i = Activator.CreateInstance<T>();
return i.TryParse(s, out error);
}
To iterate over each meta data separately I use this function:
bool parseMDs(Stream s, out string errorMessage)
{
MDs = new Dictionary<byte[], OzGGUF_MD>(new OzMDStrComparer());
MDList = new List<OzGGUF_MD>();
int count = (int)MDCount.Value;
for (int i = 0; i < count; i++)
{
var md = new OzGGUF_MD();
if (!md.TryParse(s, out errorMessage)) return false;
MDs.Add(md.MDName.Bytes, md);
MDList.Add(md);
}
errorMessage = null;
return true;
}
For which the OzGGUF_MD class is as follows:
public class OzGGUF_MD : OzGGUF_Item
{
public OzGGUF_String MDName;
public OzGGUF_MDType MDType;
public OzGGUF_Item MDValue;
public override bool Parse(Stream s, out string error)
{
MDName = new OzGGUF_String();
MDType = new OzGGUF_MDType();
if (!MDName.Parse(s, out error)) return false;
if (!MDType.Parse(s, out error)) return false;
if (!ParseMDValue(s, MDType, out MDValue, out error)) return false;
return true;
}
public static bool ParseMDValue(Stream s, OzGGUF_MDType mdType, out OzGGUF_Item mdValue, out string error)
{
switch (mdType.Format)
{
case OzGGUF_MDType.MDTFormat.STRING: //8
mdValue = new OzGGUF_String();
mdValue.Parse(s, out error);
break;
case OzGGUF_MDType.MDTFormat.INT32: //5
mdValue = new OzGGUF_Int32();
if (!mdValue.Parse(s, out error))
return true;
break;
… [more datatypes follow]
default:
error = "Unknown Meta Data format";
mdValue = null;
return false;
}
error = "";
return true;
}
public override string ToString()
{
if (MDName == null) return base.ToString();
var s = new StringBuilder();
s.Append(MDName.ToString());
s.Append(": ");
s.Append(MDValue.ToString());
return s.ToString();
}
}
Each class has its own implementation of parsing and here is the string class’s to provide an example:
public class OzGGUF_String : OzGGUF_Item
{
public string Value
{
get
{
return Encoding.UTF8.GetString(Bytes);
}
set
{
Bytes = Encoding.UTF8.GetBytes(value);
}
}
public override bool Parse(Stream s, out string error)
{
var stringLength = new OzGGUF_UInt64();
if (!stringLength.Parse(s, out error)) return false;
Bytes = new byte[stringLength.Value];
var bytesRead = s.Read(Bytes, 0, (int)stringLength.Value);
if (bytesRead != (int)stringLength.Value)
{
error = "Could not read Int64. End of stream reached.";
return false;
}
error = null;
return true;
}
public override string ToString()
{
return Value.ToString();
}
}
Next, the tensor headers are parsed as follows:
bool parseTensors(Stream s, out string errorMessage)
{
TensorNamesToID = new Dictionary<string, int>();
Tensors = new List<OzGGUF_Tensor>();
for (ulong i = 0; i < TensorCount.Value; i++)
{
if (!ReadTo(s, out OzGGUF_Tensor tensor, out errorMessage)) return false;
Tensors.Add(tensor);
TensorNamesToID.Add(tensor.Name.Value, Tensors.Count-1);
}
errorMessage = null;
return true;
}
Finally, the tensor header class is as follows:
public class OzGGUF_Tensor : OzGGUF_Item
{
public OzGGUF_String Name;
public OzGGUF_UInt32 DimCount; // Number of Dimensions
public List<OzGGUF_UInt64> ElementCounts; // Size of Each Dimension
public OzGGUF_NumType Type; // Float Precision Level/Quantization Type of the Data
public OzGGUF_UInt64 DataOffset; // Data Location in File
ulong _byteCount;
public ulong ByteCount
{
get {
if (_byteCount>0) return _byteCount;
_byteCount = GetTensorByteCount();
return _byteCount;
}
set {
_byteCount= value;
}
}
public ulong PositionInFile;
public ulong PositionInMemory;
public ulong PaddingAfter;
public byte[] Data;
public override bool Parse(Stream input, out string error)
{
Name = new OzGGUF_String();
DimCount = new OzGGUF_UInt32();
if (!Name.Parse(input, out error)) return false;
if (!DimCount.Parse(input, out error)) return false;
ElementCounts = new List<OzGGUF_UInt64>();
for (uint i = 0; i < DimCount.Value; i++)
{
ElementCounts.Add(new OzGGUF_UInt64());
ElementCounts[(int)i].Parse(input, out error);
}
Type = new OzGGUF_NumType();
DataOffset = new OzGGUF_UInt64();
if (!Type.Parse(input, out error)) return false;
if (!DataOffset.Parse(input, out error)) return false;
return true;
}
public ulong GetTensorByteCount()
{
ulong val = GetNumCount();
var type = Type.ToAINumType();
var inst = type.Create();
val = inst.CalcSize(val);
return val;
}
public ulong GetNumCount()
{
ulong val = 1;
for (int j = 0; j < DimCount.Value; j++)
{
val *= ElementCounts[j].Value;
}
return val;
}
public override string ToString()
{
var res = Name.Value + ": "+ Type.ToString()+ "[";
for (uint i = 0; i < DimCount.Value; i++)
{
res += ElementCounts[(int)i].Value + "x";
}
return res.Substring(0, res.Length - 1) + "]";
}
}
Tensors
Afterwards, reading the tensors is the relatively simple process of finding the correct location in the file and reading .GetTensorByteCount() number of bytes.
Here is the code that does so:
public bool LoadTensorFromStream(FileStream s, out string error)
{
// Load tensor data
parseDataAlignment();
if (!skipPadding(s, out error)) return false;
_tensDataOffset = s.Position;
if (!loadTensorDataBlocks(s, out error)) return false;
return true;
}
There is some padding between the tensors and the metadata, and also between the tensors themselves which can be calculated using the alignment metadata entry.
void parseDataAlignment()
{
var bytes = Encoding.UTF8.GetBytes("general.alignment");
if (!MDs.ContainsKey(bytes))
{
DataAlignement = 32;
return;
}
var md = MDs[bytes].MDValue as OzGGUF_UInt32;
DataAlignement = md.Value;
}
Next we calculate the padding size and skip it:
bool skipPadding(FileStream s, out string error)
{
try
{
var padding = DataAlignement - ((uint)s.Position % DataAlignement);
if (padding == DataAlignement)
{
error = "";
return true;
}
if (s.Length < s.Position + padding)
{
error = "The file does not contain tensor data.";
return false;
}
s.Position += padding;
error = null;
return true;
}
catch (Exception e)
{
error = "Could not seek to data. " + e.Message;
return false;
}
}
Then follows the trivial process of copying the data into the correct tensor classes:
bool loadTensorDataBlocks(FileStream s, out string error)
{
try
{
var size = calcSize((ulong)s.Position);
for (int i = 0; i < (int)TensorCount.Value; i++)
{
var tensor = Tensors[i];
var offset = (ulong)_tensDataOffset + tensor.DataOffset.Value;
tensor.Data = loadTensorData(s, offset, tensor.ByteCount);
}
error = null;
return true;
}
catch (Exception e)
{
error = "Loading Tensor Data into memory failed: " + e.Message;
return false;
}
}
byte[] loadTensorData(FileStream s, ulong offset, ulong size)
{
var ret = new byte[size];
s.Seek((long)offset, SeekOrigin.Begin);
s.Read(ret, 0, (int)size);
return ret;
}
ulong calcSize(ulong tensorDataOffset)
{
ulong position = 0;
for (int i = 0; i < (int)TensorCount.Value; i++)
{
var tensor = Tensors[i];
var byteCount = tensor.ByteCount;
tensor.PositionInFile = tensorDataOffset + position;
tensor.PositionInMemory = position;
tensor.PaddingAfter = DataAlignement - (byteCount % DataAlignement); //getObjPadding(byteCount) - byteCount;
position += byteCount + tensor.PaddingAfter;
}
return position;
}
Architecture Based Repartitioning
However, my code leaves room to implement higher levels of parallism, which do not have to guess at splices, tansposes and sparse tensors to find the correct data, by splitting up all the large tensors into Vectors and Matrices.
This is of course architecture dependant, so now we will visit the architecture part of my code that implements the llama3 architecture from scatch.
The first step is to make sure all the GGUF_MD classes have there values parsed into the correct places. This is done by the following piece of code (has to be overridden per each architecture):
public override bool InitFromFile(OzGGUFFile file, out string error)
{
if (!file.GetMDUInt32($"{Name}.context_length", out ContextLength, out error))
return false;
// Embedding Architecture
if (!file.GetMDUInt32($"{Name}.embedding_length", out EmbeddingLength, out error))
return false;
// Architecture Specific Init
if (!ArchInitialize(file, out error)) return false;
error = null;
return true;
}
protected override bool ArchInitialize(OzGGUFFile file, out string error)
{
if (!initExecManager(out error)) return false;
if (!GetRMSHParams(Mode, file, out var rmsHParams, out error)) return false;
if (!GetAttnHParams(Mode, file, out var attnHParams, out error)) return false;
if (!GetGLUHParams(Mode, file, out var gluHParams, out error)) return false;
var layerHParams = createLayerHParams(rmsHParams, attnHParams, gluHParams);
if (!GetModelSize(file, attnHParams, out error)) return false;
var modelMem = new OzAIMemNode();
if (!GetEmbeddings(file, modelMem, out error)) return false;
Layers = new List<OzAILayer_LLama>();
for (int i = 0; i < LayerCount; i++)
{
if (!createLayerParams(file, i, modelMem, layerHParams, out var layerParams, out error)) return false;
if (!createLayer(layerParams, out error)) return false;
}
}
Here we make our first encounter with the execution manager. This is the class that manages low-level operations like vector addition, Hadamard products etc.
bool initExecManager(out string error)
{
if (!OzAIProcMode.GetDefaults(out Mode, out error))
return false;
ExecManager = new OzAIExecManager();
if (!ExecManager.Init(Mode, out error)) return false;
return true;
}
Next is simply collecting hyper-parameters like the epsilon for the RMS Norm or the Theta-base for the RoPE.
bool GetRMSHParams(OzAIProcMode mode, OzGGUFFile file, out OzAIRMSNorm.CompHParams res, out string error)
{
res = null;
if (!file.GetMDFloat32($"{Name}.attention.layer_norm_rms_epsilon", out var epsilonF, out error))
return false;
if (!OzAIScalar.CreateFloat(epsilonF, mode, out var epsilon, out error))
return false;
res = new OzAIRMSNorm.CompHParams()
{
Epsilon = epsilon
};
return true;
}
bool GetAttnHParams(OzAIProcMode mode, OzGGUFFile file, out OzAIMultiHeadAttn.CompHParams hparams, out string error)
{
hparams = null;
var ropeParams = new OzAIRoPE.CompHParams();
if (!ropeParams.InitFromFile(mode, file, out error)) return false;
var headParams = new OzAIAttnHead.CompHParams();
headParams.RoPEParams = ropeParams;
if (!headParams.SetDefaults(mode, out error)) return false;
var groupParams = new OzAIAttnGroup.CompHParams();
groupParams.HeadParams = headParams;
if (!file.GetMDUInt32($"{Name}.attention.head_count", out var totalHeadCount, out error))
return false;
if (!file.GetMDUInt32($"{Name}.attention.head_count_kv", out var groupCount, out error, false, totalHeadCount) && error != null)
return false;
groupParams.HeadCount = totalHeadCount / groupCount;
hparams = new OzAIMultiHeadAttn.CompHParams();
hparams.GroupParams = groupParams;
hparams.GroupCount = groupCount;
return true;
}
bool GetGLUHParams(OzAIProcMode mode, OzGGUFFile file, out OzAIGLU.CompHParams res, out string error)
{
res = new OzAIGLU.CompHParams()
{
ActivationParams = null,
FFNLength = 8192
};
error = null;
return true;
}
This code was directly taken from llama.cpp to detect the size of the model:
bool GetModelSize(OzGGUFFile file, OzAIMultiHeadAttn.CompHParams hparams, out string error)
{
uint groupCount = hparams.GroupCount;
uint headCount = hparams.GroupParams.HeadCount * hparams.GroupCount;
if (!file.GetMDUInt32($"{Name}.block_count", out LayerCount, out error))
return false;
switch (LayerCount)
{
case 16: Size = OzAIModelSize.PCount1B; break; // Llama 3.2 1B
case 22: Size = OzAIModelSize.PCount1B; break;
case 26: Size = OzAIModelSize.PCount3B; break;
case 28: Size = OzAIModelSize.PCount3B; break; // Llama 3.2 3B
//llama.cpp: granite uses a vocab with len 49152
case 32:
uint vocabSize;
if (!file.GetMDUInt32($"{Name}.vocab_size", out vocabSize, out error, false))
{
if (error != null)
return false;
if (!file.GetMDUInt32($"tokenizer.ggml.tokens", out vocabSize, out error))
return false;
}
Size = vocabSize == 49152 ? OzAIModelSize.PCount3B : (vocabSize < 40000 ? OzAIModelSize.PCount7B : OzAIModelSize.PCount8B);
break;
case 36: Size = OzAIModelSize.PCount8B; break; //llama.cpp: granite
case 40: Size = OzAIModelSize.PCount13B; break;
case 48: Size = OzAIModelSize.PCount34B; break;
case 60: Size = OzAIModelSize.PCount30B; break;
case 80: Size = headCount == groupCount ? OzAIModelSize.PCount65B : OzAIModelSize.PCount70B; break;
default: Size = OzAIModelSize.UNKNOWN; break;
}
return true;
}
Here we see our first instance of reading in a vector. GetVectors, and the other similar functions just reinterpret the tensor data as the given type. IParam means instance parameters from here on.
bool GetEmbeddings(OzGGUFFile file, OzAIMemNode output, out string error)
{
if (!file.GetVectors("token_embd.weight", Mode, out var embeddings, out error))
return false;
Embedding = new OzAIEmbedding();
var embedMem = new OzAIEmbedding.CompMem()
{
Outputs = output
};
var embedIParams = new OzAIEmbedding.CompIParams()
{
ExecManager = ExecManager,
Embeddings = embeddings.ToArray()
};
var embedParams = new OzAICompParams()
{
Mem = embedMem,
IParams = embedIParams,
HParams = null
};
if (!Embedding.Init(embedParams, out error))
return false;
return true;
}
The rest of the code just does the same for the different components of each layer:
bool createLayerParams(OzGGUFFile file, int i, OzAIMemNode modelMem, OzAILayer_LLama.CompHParams hParams, out OzAICompParams res, out string error)
{
res = null;
var layerMem = createLayerMem(modelMem);
if (!createLayerIParams(file, i, hParams, out var layerIParams, out error))
return false;
res = new OzAICompParams()
{
Mem = layerMem,
IParams = layerIParams,
HParams = hParams,
};
return true;
}
OzAICompIOMem_Unary createLayerMem(OzAIMemNode modelMem)
{
return new OzAICompIOMem_Unary()
{
Inputs = modelMem,
Outputs = modelMem
};
}
bool createLayerIParams(OzGGUFFile file, int i, OzAILayer_LLama.CompHParams hParams, out OzAILayer_LLama.CompIParams res, out string error)
{
res = new OzAILayer_LLama.CompIParams();
res.ExecManager = ExecManager;
// RMS
if (!file.GetVector($"blk.{i}.attn_norm.weight", Mode, out var attnNorm, out error, false))
return false;
res.AttnNorm = createRMSIParams(Mode, attnNorm);
// Attn
if (!createAttnIParams(file, Mode, i, hParams.Attn, out res.Attn, out error))
return false;
// RMS
if (!file.GetVector($"blk.{i}.ffn_norm.weight", Mode, out var gluNorm, out error, false))
return false;
res.GLUNorm = createRMSIParams(Mode, gluNorm);
// GLU
if (!createGLUIParams(file, i, out res.GLU, out error))
return false;
return true;
}
bool createGLUIParams(OzGGUFFile file, int i, out OzAIGLU.CompIParams res, out string error)
{
res = null;
if (!file.GetMatrix($"blk.{i}.ffn_up.weight", Mode, out var top, out error))
return false;
if (!file.GetMatrix($"blk.{i}.ffn_gate.weight", Mode, out var gate, out error))
return false;
if (!file.GetMatrix($"blk.{i}.ffn_down.weight", Mode, out var bottom, out error))
return false;
var activation = new OzAISwish1();
var actParams = new OzAICompIParams_ExecOnly() { ExecManager = ExecManager };
res = new OzAIGLU.CompIParams()
{
ExecManager = ExecManager,
Activation = activation,
ActivationParams = actParams,
WeightsTop = top,
WeightsBottom = bottom,
WeightsGate = gate
};
error = null;
return true;
}
bool createAttnIParams(OzGGUFFile file, OzAIProcMode mode, int i, OzAIMultiHeadAttn.CompHParams hparams, out OzAIMultiHeadAttn.CompIParams res, out string error)
{
res = null;
if (!file.GetMatrix($"blk.{i}.attn_output.weight", Mode, out var output, out error))
return false;
if (!getAttnGroupsIParams(file, i, hparams, out var groups, out error))
return false;
res = new OzAIMultiHeadAttn.CompIParams()
{
ExecManager = ExecManager,
GroupParams = groups,
OutputWeights = output
};
if (!res.SetDefaults(mode, out error))
return false;
error = null;
return true;
}
bool getAttnGroupsIParams(OzGGUFFile file, int layerIdx, OzAIMultiHeadAttn.CompHParams hparams, out OzAIAttnGroup.CompIParams[] res, out string error)
{
res = null;
if (!file.GetMatricies($"blk.{layerIdx}.attn_k.weight", Mode, out var keys, (int)hparams.GroupCount, out error))
return false;
if (!file.GetMatricies($"blk.{layerIdx}.attn_v.weight", Mode, out var values, (int)hparams.GroupCount, out error))
return false;
res = new OzAIAttnGroup.CompIParams[hparams.GroupCount];
for (int i = 0; i < hparams.GroupCount; i++)
{
if (!getAttnHeadIParams(file, layerIdx, i, hparams, out var headParams, out error))
return false;
res[i] = new OzAIAttnGroup.CompIParams()
{
ExecManager = ExecManager,
KeyWeights = keys[i],
ValueWeights = values[i],
HeadParams = headParams,
};
}
return true;
}
bool getAttnHeadIParams(OzGGUFFile file, int layerIdx, int groupIdx, OzAIMultiHeadAttn.CompHParams hparams, out OzAIAttnHead.CompIParams[] res, out string error)
{
res = null;
var totalHeadCount = hparams.GroupCount * hparams.GroupParams.HeadCount;
if (!file.GetMatricies($"blk.{layerIdx}.attn_q.weight", Mode, out var querys, (int)totalHeadCount, out error))
return false;
var queryOffset = groupIdx * (int)hparams.GroupParams.HeadCount;
res = new OzAIAttnHead.CompIParams[hparams.GroupParams.HeadCount];
for (int i = 0; i < hparams.GroupParams.HeadCount; i++)
{
res[i] = new OzAIAttnHead.CompIParams()
{
ExecManager = ExecManager,
QueryMat = querys[queryOffset + i],
};
}
return true;
}
OzAIRMSNorm.CompIParams createRMSIParams(OzAIProcMode mode, OzAIVector gain)
{
if (!OzAIScalar.CreateFloat(1f, mode, out var part, out string error))
return null;
return new OzAIRMSNorm.CompIParams()
{
ExecManager = ExecManager,
Part = part,
Gain = gain
};
}
bool createLayer(OzAICompParams layerParams, out string error)
{
var layer = new OzAILayer_LLama();
if (!layer.Init(layerParams, out error))
return false;
Layers.Add(layer);
return true;
}
Finally, the rest of the code just does the same for the output operations:
bool createOutNorm(OzGGUFFile file, OzAIMemNode modelMem, OzAIRMSNorm.CompHParams hparams, out string error)
{
OutNorm = new OzAIRMSNorm();
var outNormMem = new OzAICompIOMem_Unary()
{
Inputs = modelMem,
Outputs = modelMem
};
if (!file.GetVector("output_norm.weight", Mode, out var outNorm, out error, false))
return false;
var outNormIParams = createRMSIParams(Mode, outNorm);
var rmsParams = new OzAICompParams()
{
Mem = outNormMem,
IParams = outNormIParams,
HParams = hparams
};
if (!OutNorm.Init(rmsParams, out error))
return false;
return true;
}
bool createUnembedding(OzGGUFFile file, OzAIMemNode modelMem, out string error)
{
var unembedMem = new OzAIUnembedding.CompMem()
{
Inputs = modelMem
};
if (!OzAIIntVec.Create(Mode, out unembedMem.Output, out error))
return false;
var unembedIParams = new OzAIUnembedding.CompIParams()
{
ExecManager = ExecManager,
Embeddings = Embedding.IParams.Embeddings
};
var unembedHParams = new OzAIUnembedding.CompHParams()
{
VocabSize = (ulong)Embedding.IParams.Embeddings.LongLength
};
var unembedParams = new OzAICompParams()
{
Mem = unembedMem,
IParams = unembedIParams,
HParams = unembedHParams
};
Unembedding = new OzAIUnembedding();
if (!Unembedding.Init(unembedParams, out error))
return false;
return true;
}