AI TokenTree, an Efficient Tokenizer for LLMs
by Gyula Rabai
Tokenization is the process of converting text into tokens for Large Language Models (LLM). The most common approach in the industry to implement byte-pair encoding is using Regular Expressions (RegExp). The tokenizer I have implemented is significantly faster, as it uses a different processing aproach, which relies on the assumption that larger tokens will be less frequent than their constituent parts. It builds a so called token-tree (a string-tree like structure), and walks this tree to do the tokenization instead of using regular expressions. This data modelling and execution approach provides a significant perfmance increase over traditinal tokenizers. This tokenizer is used in my AI Infernece Engine for LLMs.
Why is this tokenization model significant?
Because the algorithm of this tokenization method offers up to 100x faster performance to current tokenization systems used in LLM inference.
Please read the paper: Fast Inference-Time Tokenization through Approximating BPE
Download
Download (exe): Token-Tree.zip
Download (source): Token-Tree-Source.zip
Github: https://github.com/mrgyularabai/Token-Tree
What is a "TokenTree"
A "Token Tree" is a "Decision tree". It is a tree like data structure that makes tokenization in LLMs more efficient.
The core idea is to create a tree structure to speed up decision making and finding the tokens. By eliminating a large set of tokens in each layer we can efficiently find the apprpriate token number for each word, word part or symbol.
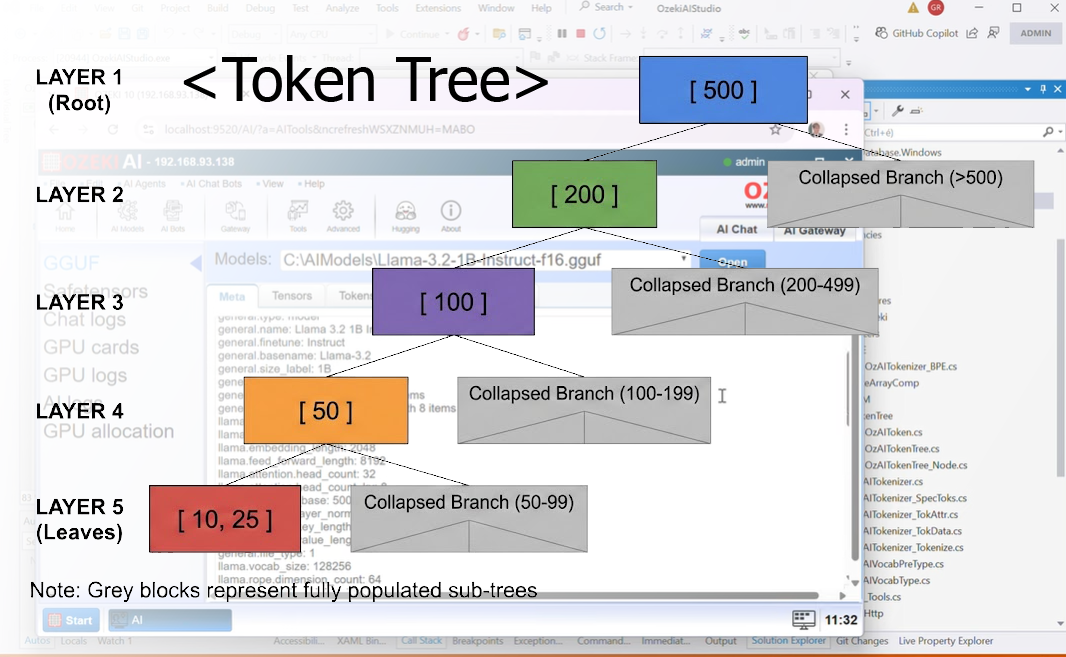
TokenTree Tokenization (Console application)
TokenTree Tokenization (Console application, with breakpoints)
TokenTree Tokenization (GUI application)
TokenTree Tokenization (GUI application, with breakpoints)
Token Tree Tokenization Explained
The tokenization process relies on a few assumptions to implement a more performant approach than the traditional byte-pair-encoding (BPE) implentations:
1) Most token boundaries will fall on natural text boundaries such as word spaces and sentence ending periods.
2) Most longer tokens have a lower frequency than shorter tokens.
3) Even if a tokenization error occurs the model can still produce a usable output.
Assumption 3 is grounded in the fact that bigram models can still produce coherent text despite tokenization not accomodating for the natural meaning and structure of texts. Given this assumption, one can safely use a tokenization model that is only an approximation of what the full BPE merge rule-set would introduce and still get a very good output.
Assumptions number 1 and 2 garantee that a normal greedy approach to searching for tokens will either eventually self-correct (1) or produce the correct output regardless of ignoring merge-rules (2).
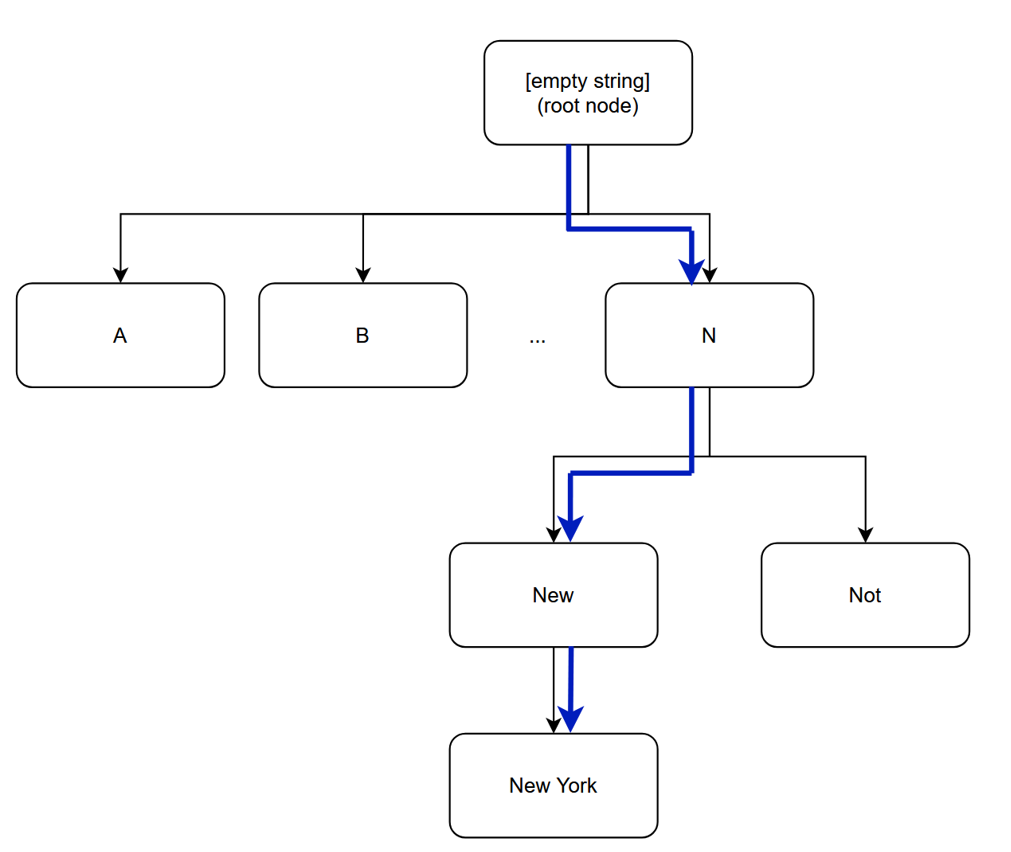
The approach I propose is as follows: one should build a token tree where one represents all possible tokens as a series of merges of previous tokens. Thus by traversing this B-Tree like structure whilst iterating over the characters of the text, one can achieve a linear time tokenization assuming that the decision at each branching of the tree is also linear time.
To make this approach even more efficient, it is sufficient to make each child node a continuation of the parent node where ’New’ is a continuation of ’N’. Then, as we natrually iterate through the caracters of the text, we can check whether a longer token is possible in the text (providing accuracy through assumption 2) or whether the text differs from the provided continuations which marks the end of the token (providing accuracy through assuption 1). The following figure illustrates an example of this so called Token Tree approach for tokenizing the word ’New York’ (part of the llama3 vocabulary):
For all the small scale test that I have performed, it has produced completely accurate results without any more pre- or post-processing required of the text at a sixfold increase in performance compared to llama.cpp’s traditional implementation in C++ (note that the GUI has a very limited refresh rate for the framework I am using). For the decisions at the branches, I use a hash-table (with taking the last few chars of each string as the hash), so that the amortized time complexity remains linear.
Supported LLM Architectures
| Type | Value | Description | Support Status |
|---|---|---|---|
NONE |
0 | Models without vocabulary | Not Supported |
SPM |
1 | LLaMA tokenizer based on byte-level BPE with byte fallback | Fully Supported |
BPE |
2 | GPT-2 tokenizer based on byte-level BPE | Fully Supported |
WPM |
3 | BERT tokenizer based on WordPiece | Not Supported |
UGM |
4 | T5 tokenizer based on Unigram | Not Supported |
Usage Examples
// Load tokenizer from GGUF file
if (OzAITokenizer.CreateFromFile(ggufFile, out var tokenizer, out string error))
{
// Tokenize text
tokenizer.GetTokens("Hello, world!", out var tokens, out var times);
}
Unerstanding key parts of the tokenization source code
Tokenization is the first step in the Inference. The Infer function of my AI inference engine firsts loads the model and builds the token tree. When a new text is entered as input the token tree is used to do the Tokenization.
OzAIModel_Ozeki _model;
string Infer(string text)
{
OzLogger.Log(OzAILogger.LogSourceGy, LogLevel.Information, "Infer called with text: " + text);
if (_model == null)
{
_model = new OzAIModel_Ozeki();
_model.modelPath = GGUF.FileName;
}
try
{
_model.Start(out var error);
if (error != null)
return error;
// Tokenization
if (!_model.Tokenizer.GetTokens(text, out var inputTokens, out var times, out error))
{
return error;
}
// Inference
if (!_model.infer(inputTokens, out var outputTokens, out var errorInfer))
{
return errorInfer;
}
var res = _model.Tokenizer.GetStringsRaw(outputTokens);
return res;
}
catch (Exception ex)
{
return "Error: " + ex.Message;
}
}
The model is created if it is not already. Then, a thread safe function is called ’_model.Start,’ which initializes the model (this only happens once) as follows:
protected override bool PerformStart(out string error)
{
if (!loadModel(modelPath, out GGUFFile, out var errorMessage))
{
error = "Model loaded failed. " + errorMessage;
return false;
}
if (!GGUFFile.LoadTensors(out error))
return false;
if (!InitFromFile(GGUFFile, out var errorTok))
{
error = "Model Initialization failed. " + errorTok;
return false;
}
error = null;
return true;
}
public bool InitFromFile(OzGGUFFile gguf, out string error, uint batchSize = 512)
{
GGUFFile = gguf;
BatchSize = batchSize;
if (!GGUFFile.GetMDString("general.name", out ModelName, out error))
return false;
// Initialize Architecture Data
if (!OzAIArch.CreateFromFile(GGUFFile, out Architecture, out error))
{
error = "Could not read architectural information. " + error;
return false;
}
// Initialize Tokenizer
if (!OzAITokenizer.CreateFromFile(GGUFFile, out this.Tokenizer, out error))
{
error = "Failed to create the tokenizer. " + error;
return false;
}
return true;
}
All the data is loaded from the files into memory and along with the correct architecture based on the metadata, but most crucially, OzAITokenizer.CreateFromFile() is called, which initializes the tokenizer whose initialization code can be seen in the following class:
public abstract partial class OzAITokenizer
{
// Space Escaping
public string SpaceEscape
{
get
{
return GetSpaceEscape();
}
}
protected abstract string GetSpaceEscape();
public string UnescapeSpace(string text)
{
return text.Replace(SpaceEscape, " ");
}
// Initialization
public static bool CreateFromFile(OzGGUFFile file, out OzAITokenizer res, out string error)
{
res = null;
// Get tokenizer model name
string model;
if (!file.GetMDString($"tokenizer.ggml.model", out model, out error))
return false;
//llama.cpp supports: 'no_vocab', 'llama', 'bert', 't5'
switch (model)
{
case "gpt2":
res = new OzAITokenizer_BPE();
break;
case "llama":
res = new OzAITokenizer_SPM();
break;
default:
error = $"Tokenizer model {model} not recognized.";
return false;
}
if (!res.InitFromFile(file, out error)) return false;
return true;
}
protected abstract bool ModelInit(OzGGUFFile file, out string error);
public bool InitFromFile(OzGGUFFile file, out string error)
{
if (!ModelInit(file, out error)) return false;
if (!getTokData(file, out error)) return false;
if (!ReadTokenIDFromMD(file, $"tokenizer.ggml.unknown_token_id", ref Unkown, out error))
return false;
buildTokTree();
if (!handleSepecialTokens(file, out error)) return false;
//if (!handleTokenAttrs(file, out error)) return false;
return true;
}
public void buildTokTree()
{
TokenTree = new OzAITokenTree(Unkown);
while (Len2ID.Count != 0)
{
var val = Len2ID.Dequeue();
var tok = Tokens[val];
TokenTree.Add(tok);
}
}
}
Focusing in on the BPE implementation:
public class OzAITokenizer_BPE : OzAITokenizer
{
protected override string GetSpaceEscape()
{
return "Ġ";
}
protected override bool ModelInit(OzGGUFFile file, out string error)
{
BeginningOfSequence = 11;
EndOfSequence = 11;
Unkown = -1;
Separator = -1;
Padding = -1;
Classification = -1;
Mask = -1;
AddSpacePrefix = false;
AddBOS = true;
error = null;
return true;
}
Stopwatch sw = new Stopwatch();
protected override bool Tokenize(string text, List<int> tokens, out string times, out string error, bool allowUnk)
{
times = null;
sw.Start();
if (!mergeBytes(text, tokens, allowUnk, out error)) return false;
sw.Stop();
var tokensPerSec = Math.Round(tokens.Count / (sw.Elapsed.TotalMilliseconds / 1000));
times = tokensPerSec.ToString();
error = null;
return true;
}
bool mergeBytes(string text, List<int> tokens, bool allowUnks, out string error)
{
error = null;
if (text == null || text.Length == 0)
return true;
var bytes = Encoding.UTF8.GetBytes(text);
for (int i = 0; i < bytes.Length; i++)
{
var len = Math.Min(bytes.Length - i, MaxTokenLen);
var val = new byte[MaxTokenLen];
Buffer.BlockCopy(bytes, i, val, 0, len);
if (!TokenTree.Get(val, out var res))
{
if (!resolveUnk(val[0], allowUnks, tokens, out error))
return false;
continue;
}
tokens.Add(res);
i += Tokens[res].Text.Length - 1;
}
return true;
}
bool resolveUnk(byte text, bool allowUnks, List<int> res, out string error)
{
if (allowUnks)
{
res.Add(Unkown);
error = null;
return true;
}
if (!Byte2TokenID(text, out int id, out error))
return false;
res.Add(id);
error = null;
return true;
}
}
The tokens per sec is measured for the tokenization algorithm (that is what is displayed in the tokenization tab for my program). The key function in the above is TokenTree.Get(), which is applied to each remaining section of the text iteratively. Recalling how OzAITokenizer.InitFromFile() initialized the token data from the file. The way it did this was by creating a list of OzAITokens from the file, each with a token id and a string. Then it sorted these tokens in order of length. Here is the code for OzAIToken:
public class OzAIToken
{
public int ID;
public byte[] Text;
public float Score; // the 'frequency' of a token
public override string ToString()
{
var sb = new StringBuilder();
sb.Append(ID);
sb.Append(": \"");
sb.Append(Encoding.UTF8.GetString(Text));
sb.Append("\"");
return sb.ToString();
}
}
Here is the rest of the code for getting the token data from the file:
public List<OzAIToken> Tokens;
public PriorityQueue<int, int> Len2ID;
public OzAITokenTree TokenTree;
public int MaxTokenLen;
public float AvgTokenLen;
bool getTokData(OzGGUFFile file, out string error)
{
if (!GetTokenList(file, out error)) return false;
//if (!getTokenScores(file, out error)) return false;
//if (!getTokenTypes(file, out error)) return false;
return true;
}
public class ByteArrayComparer : IEqualityComparer<byte[]>
{
public bool Equals(byte[] left, byte[] right)
{
if (left == null || right == null)
{
return left == right;
}
if (left.Length != right.Length)
{
return false;
}
for (int i = 0; i < left.Length; i++)
{
if (left[i] != right[i])
{
return false;
}
}
return true;
}
public int GetHashCode(byte[] key)
{
return key.GetHashCode();
}
}
public bool GetTokenList(OzGGUFFile file, out string error)
{
OzGGUF_Item item;
if (!file.GetMD($"tokenizer.ggml.tokens", out item, out error, false))
return error == null;
try
{
OzGGUF_Array array = item as OzGGUF_Array;
Tokens = new List<OzAIToken>((int)array.Count.Value);
Len2ID = new PriorityQueue<int, int>((int)array.Count.Value);
for (int i = 0; i < (int)array.Count.Value; i++)
{
var token = new OzAIToken();
var text = array.Value[i] as OzGGUF_String;
var escaped = text.Value;
var unescaped = UnescapeSpace(escaped);
token.Text = Encoding.UTF8.GetBytes(unescaped);
token.ID = i;
Tokens.Add(token);
Len2ID.Enqueue(token.ID, token.Text.Length);
MaxTokenLen = Math.Max(MaxTokenLen, token.Text.Length);
AvgTokenLen += token.Text.Length;
}
AvgTokenLen /= array.Count.Value;
}
catch (Exception e)
{
error = "Failed to read the list of tokens: " + e.Message;
return false;
}
return true;
}
Next, the token tree is built, using the approach discussed in the design section. Although this initialization is O(nlogn), this is a one-time trade-off for extremely fast linear time tokenization for the rest of the tokens. The code for building the token tree takes in the sorted list (priority queue in my implementation) of tokens by length and adds them iteratively (from shortest to longest) to the tree. Here is the code for this:
public void buildTokTree()
{
TokenTree = new OzAITokenTree(Unkown);
while (Len2ID.Count != 0)
{
var val = Len2ID.Dequeue();
var tok = Tokens[val];
TokenTree.Add(tok);
}
}
For which the TokenTree class looks like this:
public class OzAITokenTree
{
OzAITokenTree_Node root;
public OzAITokenTree(int unk)
{
root = new OzAITokenTree_Node(unk);
}
public void Add(OzAIToken token)
{
var val = new OzAITokenTree_Node(token.ID);
var res = new byte[token.Text.Length];
Buffer.BlockCopy(token.Text, 0, res, 0, res.Length);
var current = root;
while (current != null)
{
current = current.AddChild(ref res, val);
}
}
public bool Get(byte[] data, out int res)
{
var addition = data;
var current = root;
res = root.ID;
while (current != null)
{
res = current.ID;
current = current.TryToken(ref addition);
}
return res != root.ID;
}
}
The class for a node also goes as follows:
public class OzAITokenTree_Node
{
public int ID { get; set; }
public Dictionary<byte[], OzAITokenTree_Node> Children { get; set; }
public List<int> Lengths;
public OzAITokenTree_Node(int id)
{
ID = id;
Lengths = new List<int>();
Children = new Dictionary<byte[], OzAITokenTree_Node>(new OzByteArrayComparer());
}
public OzAITokenTree_Node AddChild(ref byte[] addition, OzAITokenTree_Node child)
{
if (addition.Length == 0)
return null;
var res = TryToken(ref addition);
if (res != null)
return res;
Children.Add(addition, child);
if (Lengths.Count == 0 || Lengths[Lengths.Count - 1] != addition.Length)
{
Lengths.Add(addition.Length);
}
return null;
}
static OzByteArrayComparer _byteArrayComparer = new OzByteArrayComparer();
public OzAITokenTree_Node TryToken(ref byte[] addition)
{
if (addition.Length == 0)
return null;
if (Lengths.Count < Children.Count)
{
for (int i = 0; i < Lengths.Count; i++)
{
if (Lengths[i] > addition.Length)
return null;
var res = new byte[Lengths[i]];
Buffer.BlockCopy(addition, 0, res, 0, Lengths[i]);
if (!Children.ContainsKey(res))
continue;
var child = Children[res];
if (addition.Length < 2)
{
addition = Array.Empty<byte>();
return child;
}
var len = addition.Length - Lengths[i];
res = new byte[len];
Buffer.BlockCopy(addition, Lengths[i], res, 0, len);
addition = res;
return child;
}
}
else
{
foreach (var item in Children.Keys)
{
if (!ContainsRange(addition, item))
continue;
var newLen = addition.Length - item.Length;
var res = new byte[newLen];
Buffer.BlockCopy(addition, item.Length, res, 0, newLen);
addition = res;
return Children[item];
}
}
return null;
}
static bool ContainsRange(byte[] data, byte[] item)
{
if (data.Length < item.Length)
return false;
for (int j = 0; j < item.Length; j++)
{
if (data[j] != item[j])
{
return false;
}
}
return true;
}
}
As one can see, TokenTree.Add and the node’s AddChild are use for constructing the tree, where as .Get and TryToken are the equivalents for using the tree to tokenize. This approach yields 53000 tokens/sec on the run shown in the YouTube video (https://www.youtube.com/watch?v=L24m2A2zZlo&t=59s) that is also linked on my website (gyularabai.com) on this project’s page.
Inference Overview
At this point we have acquire the tokens to a function-call to the tokenizer, and are calling _model.infer(). This eventually makes its way to the following forward function:
public override bool Forward(out string error)
{
Embedding.Mem.Input = IN as OzAIIntVec;
if (!Embedding.Forward(out error))
return false;
for (int i = 0; i < Layers.Count; i++)
{
var layer = Layers[i];
if (!layer.Forward(out error))
return false;
}
if (!OutNorm.Forward(out error))
return false;
if (!Unembedding.Forward(out error))
return false;
OUT = Unembedding.Mem.Output;
return true;
}
This, unsurprising, calls the respective forward function of each component of the model which were initialized in the earlier sections. Let us take a closer look at what a model architecture component actually looks like:
public abstract class OzAIArchComp : OzAICheckable
{
public OzAICompParams Params;
public abstract string Name { get; }
public bool Init(OzAICompParams args, out string error)
{
Params = args;
if (!getProcModeSafe(args, out var mode, out error)) return false;
if (!mode.DoChecks)
return InitInner(out error);
if (!args.IsPossible(out error))
{
error = $"Failed to init {Name}, becuase invalid component parameters provided: " + error;
return false;
}
if (!IsPossible(out error))
{
error = $"Failed to init {Name}, becuase the execution of this component would not be possible: " + error;
return false;
}
return InitInner(out error);
}
bool getProcModeSafe(OzAICompParams args, out OzAIProcMode mode, out string error)
{
mode = null;
if (args == null)
{
error = $"Could not init {Name}, becuase no OzAICompParams provided.";
return false;
}
if (args.IParams == null)
{
error = $"Could not init {Name}, becuase no instance params provided in OzAICompParams.";
return false;
}
if (args.IParams.ExecManager == null)
{
error = $"Could not init {Name}, becuase no exec manager provided in instance params provided in OzAICompParams.";
return false;
}
if (!args.IParams.ExecManager.GetProcMode(out mode, out error))
{
error = $"Could not init {Name}: " + error;
return false;
}
error = null;
return true;
}
protected virtual bool InitInner(out string error)
{
error = null;
return true;
}
public abstract bool Forward(out string error);
}
Firstly, it is an OzAICheckable, this means it must implement a function to check whether the operation the component needs to perform is feasible (IsPossible). Secondly, it too shares methods to access an OzAIProcMode, which is just a way to confer run-time settings between classes such as how many threads will be used. Finally, it accepts an OzAICompParams, which is what it uses for initialization. This is presented below:
/// <summary>
/// This class contains all the parameters that an architecture component needs to operate
/// </summary>
public class OzAICompParams : OzAICheckable
{
public OzAICompIOMem Mem;
public OzAICompIParams IParams;
public OzAICompHParams HParams;
public bool SetDefaults(OzAIProcMode mode, out string error)
{
if (mode.DoChecks)
{
List<object> objs = [IParams, HParams];
List<string> names = ["instance parameters", "hyperparameters"];
if (!CheckIfNull(objs, names, out error))
return false;
}
if (!IParams.SetDefaults(mode, out error)) return false;
if (!HParams.SetDefaults(mode, out error)) return false;
error = null;
return true;
}
public bool InitFromFile(OzAIProcMode mode, OzGGUFFile file, out string error)
{
if (mode.DoChecks)
{
List<object> objs = [IParams, HParams];
List<string> names = ["instance parameters", "hyperparameters"];
if (!CheckIfNull(objs, names, out error))
return false;
}
if (!IParams.InitFromFile(mode, file, out error)) return false;
if (!HParams.InitFromFile(mode, file, out error)) return false;
return false;
}
public override bool IsPossible(out string error)
{
List<object> objs = [Mem, IParams];
List<string> names = ["IO memory", "instance parameters"];
if (!CheckIfNull(objs, names, out error))
return false;
if (!Mem.IsPossible(out error)) return false;
if (!IParams.IsPossible(out error)) return false;
if (HParams != null)
{
if (!HParams.IsPossible(out error))
return false;
}
return true;
}
}
This class binds three arguments together that each architecture component needs. Firstly, each one needs access to its hyper-parameters such as epsilon for RMS Norm (OzAICompHParams). Secondly, each needs access to its respective instance’s individual parameters, like the gain weight for RMS norm (OzAICompIParams). Finally, each component needs to know where to take its inputs from and where to store the results of its calculations (OzAICompIOMem).